New Model Predicts Cancer Drug Efficacy Across and Within Cancer Types
As large multi-cancer datasets become more important for predicting who may benefit from cancer drugs, a new approach better accounts for potentially overlooked variation.
2:00 PM
Author |
The goal of "precision oncology" is to be able to tailor treatments to each individual patient based on their cancer's unique molecular fingerprints.
New technologies and large, "-omics" datasets are now allowing researchers to examine shared features not just within a single type of cancer — such as breast cancer — but to look for patterns across many types of cancer. These data offer great clues that an approach that has shown success in one type of cancer may also work well against a different type of cancer based on common underlying features.
But sifting this sea of patient data is tricky. A model that predicts a drug may work against multiple cancer types may gloss over important variation within the individual cancer types — failing to recognize it may not help certain subsets of patients.
New research from the University of Michigan Rogel Cancer Center aims to improve anti-cancer drug response predictions by teasing apart and allowing for simultaneous examination of differences across multiple cancer types as well as within individual types. The findings appear in PLOS Computational Biology.
"It's like the old argument about nature versus nurture," says study co-senior author Jun Li, Ph.D., a professor of human genetics, and associate chair for research of computational medicine and bioinformatics. "Obviously both contribute. The questions we set out to answer were: How much does each contribute? And can we use that information to make predictions that would be useful into the clinic?"
Like Podcasts? Add the Michigan Medicine News Break on iTunes or anywhere you listen to podcasts.
The study, led by former U-M postdoctoral fellow John Lloyd, Ph.D., who had worked closely with Li and co-senior author Sofia Merajver, M.D., Ph.D., used MEK inhibitor response as a proof-of-concept example, and drew on two public datasets, each containing several hundred patient-derived cancer cell lines.
The analysis — which included mRNA expression, point mutations and copy number variations — found that while predictions of drug response were highly accurate when comparing one cancer type as a whole to another cancer type, the predictions only held up for about five of 10 cancer types when looking at that cancer type on its own.
The questions we set out to answer were: How much does each contribute? And can we use that information to make predictions that would be useful into the clinic?Jun Li, Ph.D.
"What this means is that to be useful in the clinic for helping individual patients, we have to be able to incorporate both between-cancer and within-cancer data," adds co-senior author Matthew Soellner, Ph.D. an assistant professor of chemistry in the U-M College of Literature, Science, and the Arts. "Otherwise, you may capture the average response to a drug across cancer types, but completely lose where an individual patient falls within their cancer type."
For example, most colorectal cancer cell lines are sensitive to MEK inhibition, but liver cancer cell lines show a much more mixed response. So additional information and biomarkers beyond just the cancer type would be important for determining the likelihood that an individual patient with liver cancer will respond well to a MEK inhibitor.
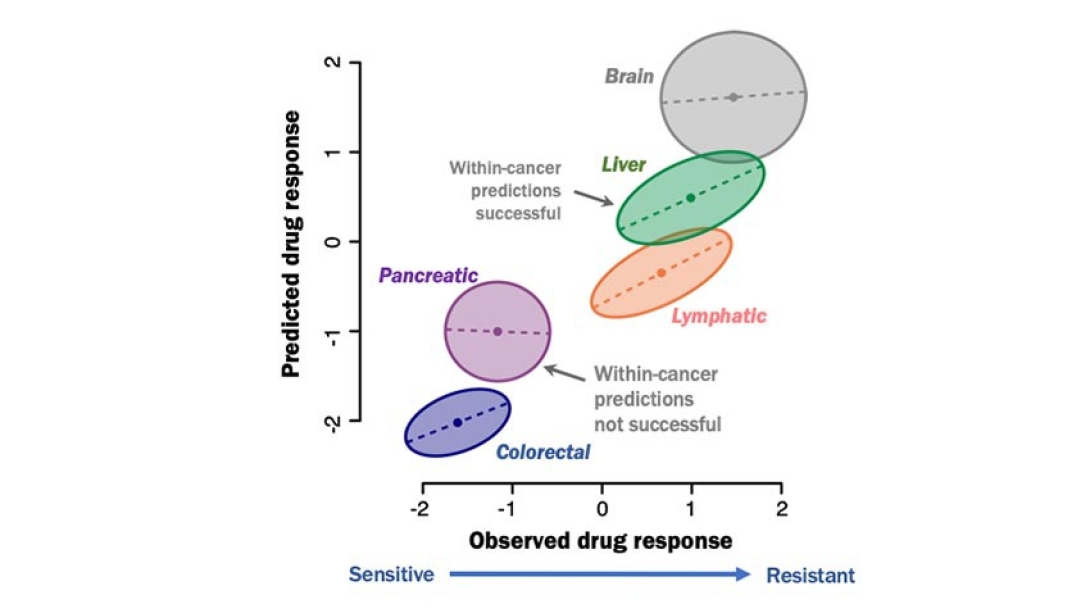
Toward this goal, the U-M team developed a visualization strategy called a "cigar plot," where differences in response between cancer types can be viewed simultaneously with responses within each type of cancer. The more elongated, or cigar-shaped, the distribution of results within an individual cancer type, the better it can be used to predict response across different individuals affected by that type of cancer — whether brain cancer or lung cancer.
"We hope that this approach can serve as a general tool for the field," says Merajver, a professor of epidemiology and of internal medicine. "More patients than ever are participating in basket clinical trials, which select based on a cancer's molecular features rather than where in the body the cancer originated, so prediction models will be increasingly important for matching patients with effective treatments."
MORE FROM THE LAB: Subscribe to our weekly newsletter
This simultaneous approach to balancing considerations of both cancer type and individual variation within a type when making treatment decisions could also be applied to other diseases that affect multiple tissues or where predictions are drawn across broad, diverse populations, the researchers note.
The work was supported by the Michigan Institute for Clinical and Health Research, Breast Cancer Research Foundation, Michigan Institute for Data Science, and National Institutes of Health (1R21CA218498-01, R01GM118928-01).
Paper cited: "Impact of between-tissue differences on pan-cancer predictions of drug sensitivity," PLOS Computational Biology. DOI: 10.1371/journal.pcbi.1008720

Health Lab
Explore a variety of health care news & stories by visiting the Health Lab home page for more articles.
Media Contact

Public Relations
Department of Communication at Michigan Medicine
Stay Informed
Want top health & research news weekly? Sign up for Health Lab’s newsletters today!
Featured News & Stories
New Clues to Classic Cancer Target Found in Immune Cells

Scientists ‘Farm’ Natural Killer Cells in Novel Cancer Fighting Approach
Toward a New Staging System for Prostate Cancer, and Why it Matters

Giving with gratitude: planned gifts support nursing, research, and patient care
Study sheds light on how early pancreas lesions become cancerous
